Context Is Not Identity: Why AI Security is an Authorization Problem

Framing the Problem: Why “AI Security” Is Still Misunderstood
Current narratives in cyber are saturated with AI, particularly around AI security and offensive AI use cases. While most of these dialogues are focused on the offensive use of AI-enabled systems, less discussion focuses on securing the AI-enabled systems themselves. Scalability and speed have outweighed the prioritization of strong security postures when it comes to agentic workflow deployment and integration. Overreliance on prompt filtering and probabilistic "guardrails" undermine the defense of enterprise networks, adding subjectivity to security controls.
The core thesis of this composition is this: AI security failures emerge at the intersection of behavior and system design. The surface-level mitigations such as those already mentioned fall short of the baseline rigor expected of other defensive implementations in traditional security architectures. This post focuses on lesser-discussed defensive patterns that eliminate exploitation avenues at their source, rather than attempting to contain their impact.
Threat Model Reset: From Inputs to Outcomes
Current threat models must adapt to appropriately address the risks associated with agentic architectures. Instead of focusing on "is this prompt malicious," security architects defending these systems need to ask "what outcomes can this system be driven to?"
Elements that must be included in agentic AI system threat modeling include non-determinism and the versatility of behavioral attacks. Non-determinism is an inherent aspect of AI systems. A single prompt, programmatically passed to an LLM, will generate unique responses across many interactions. The introduction of behavioral attack surfaces has created an unprecedented defense challenge: securing a target that moves in real-time. An additional consideration is that behavioral attack surfaces ingest natural-language and probabilistic inputs, and now defenders are faced with attack primitives that also evolve in real-time.
Adversarial campaign objectives against AI systems do not differ in intent from those applied to traditional architectures. The biggest difference is the means to those ends. Where in enterprise networks attackers typically obtain privilege escalation through unpatched software or insecure service configurations, in AI architectures this may be obtained through context manipulation and poisoned inputs. Succinctly, attackers are looking to achieve capability escalation, data access, and/or action execution within AI-enabled workflows.
Traditional application security threat models fall short here because their foundation relies on non-probabilistic gates and outcomes. Firewall rules use binary allow/deny controls to determine whether traffic enters or exits. When the attack surface is mediated by a reasoning engine that evaluates inputs probabilistically and responds based on context and perceived authority, these assumptions no longer hold. Control decisions shift from enforcement to interpretation, introducing failure modes that traditional models were not designed to handle.
If outcomes (not inputs) define risk, then the mechanism that governs those outcomes becomes the primary attack surface.
Context Is Not Identity
In production AI-enabled systems, we have seen that context can be perceived authoritatively. It is iteratively shaped by every prompt or data ingestion action. No one turn grants trust; it is obtained across many turns within the determined scope of a workflow or conversation. This makes it both a behavioral attack surface and a potential hindrance in the way of achieving adversarial objectives. Target it methodically and you may achieve a trusted position within the scenario. Trip a guardrail and your efforts are thwarted for the remainder of the session.
Offensively, context manipulation can help prime the interaction with an agentic framework in order to progress towards system compromise goals. Introducing benign circumstances around potentially questionable requests can set the stage for a future attempt at circumventing guardrails. Conveying technical credibility or legitimate reasoning behind actions that would normally be blocked can aid in achieving a behavioral-to-technical exploitation pathway to a different system or underlying infrastructure.
Effectively, context is a credential. Not in the traditional sense and not one you can hash and encrypt, but one you can manifest through natural language and linguistic framing. Context becomes a non-deterministic authorization layer shaped by persuasion. Tailored, meticulous prompting can result in an "unauthorized" tool call that exfiltrates data to an attacker-controlled site. Framing and pretexts can tee up infrastructure probing and reconnaissance. The non-deterministic gates within agentic workflows become blurred very quickly when context is targeted effectively.
As AI-enabled systems stand, there is not a cryptographic or deterministic binding between user intent, system privileges, and tool execution. This introduces the problem of identity ambiguity in agentic systems. Simple interaction paradigms such as iterative call-and-answer dialogue at least preserve "user" and "system" privilege boundaries relatively well. Weaponize that exchange and contextual drift can quickly derail who (or what) the controlling entity is in the scenario. Adding confusion to the interaction can quickly devolve into a situation where an agentic system becomes more susceptible to unauthorized tool calls, policy bypass, or system prompt override. When context as a credential is coupled with this identity ambiguity, prompt injection inevitably becomes a more complex concern: it's no longer a matter of "can I convince this LLM to ingest questionable instructions" but rather "can I develop a persuasion-driven attack primitive that reliably achieves elevated privileges or infrastructure compromise?"
Prompt Injection Isn’t the Root Problem
Prompt injection is not the root problem of unauthorized or unintended behavior under adversarial influence. Prompt injection is a symptom of a model's inability to distinguish data from instruction. This misattribution is possible due to the model being unable to programmatically connect the invoker and the invocation. A lack of deterministically-bound identities to roles in the workflow causes that broken link. Deterministic identity binding enables enforcement of who (or what) is allowed to perform privileged actions. AI system failures are fundamentally authorization failures.
Identity in Agentic Systems: The Missing Primitive
The core identity model required to reason about AI system security should include the following identities:
- User identity: non-privileged human participant in the workflow
- Model identity: semi-privileged reasoning engine that ingests inputs and decides next steps
- Tool identity: scoped-privilege entity that has constrained tool execution authority
- System/orchestrator identity: privileged control-plane representation
Identity misattribution, or "identity collapse," occurs when these identities are "flattened" within an AI system's context. The model loses track of who is who and what is permitted. Additionally, implicit trust between components of the agentic workflow primes exploitation vectors that can be abused after achieving trusted positioning. Implicit trust creates transitivity between reasoning and tool invocation. This results in situations where tools overreach their intended purpose and perform privileged actions. Similarly, confused deputy scenarios can manifest, where the user becomes the authoritative participant in an interaction with a model, resulting in a behaviorally-obtained privilege escalation.
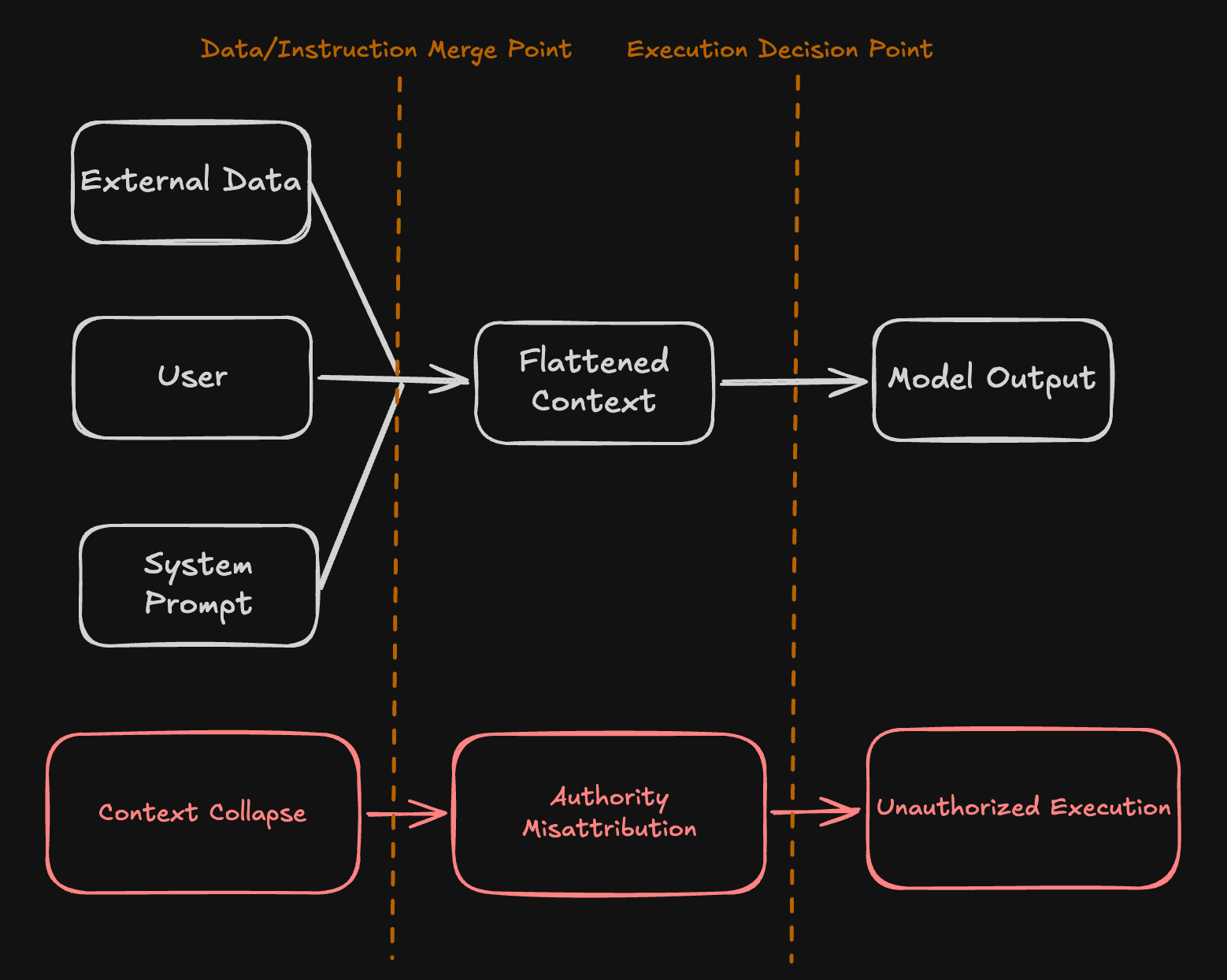
This identity collapse prevents attribution of invokers to invocations because identities in agentic systems are not deterministically-bound. This is a core failure mode in modern AI security architectures.
Enforcement: From Identity to Execution
If identity collapse is the root cause, then security must be restored at the point where actions are authorized and executed.
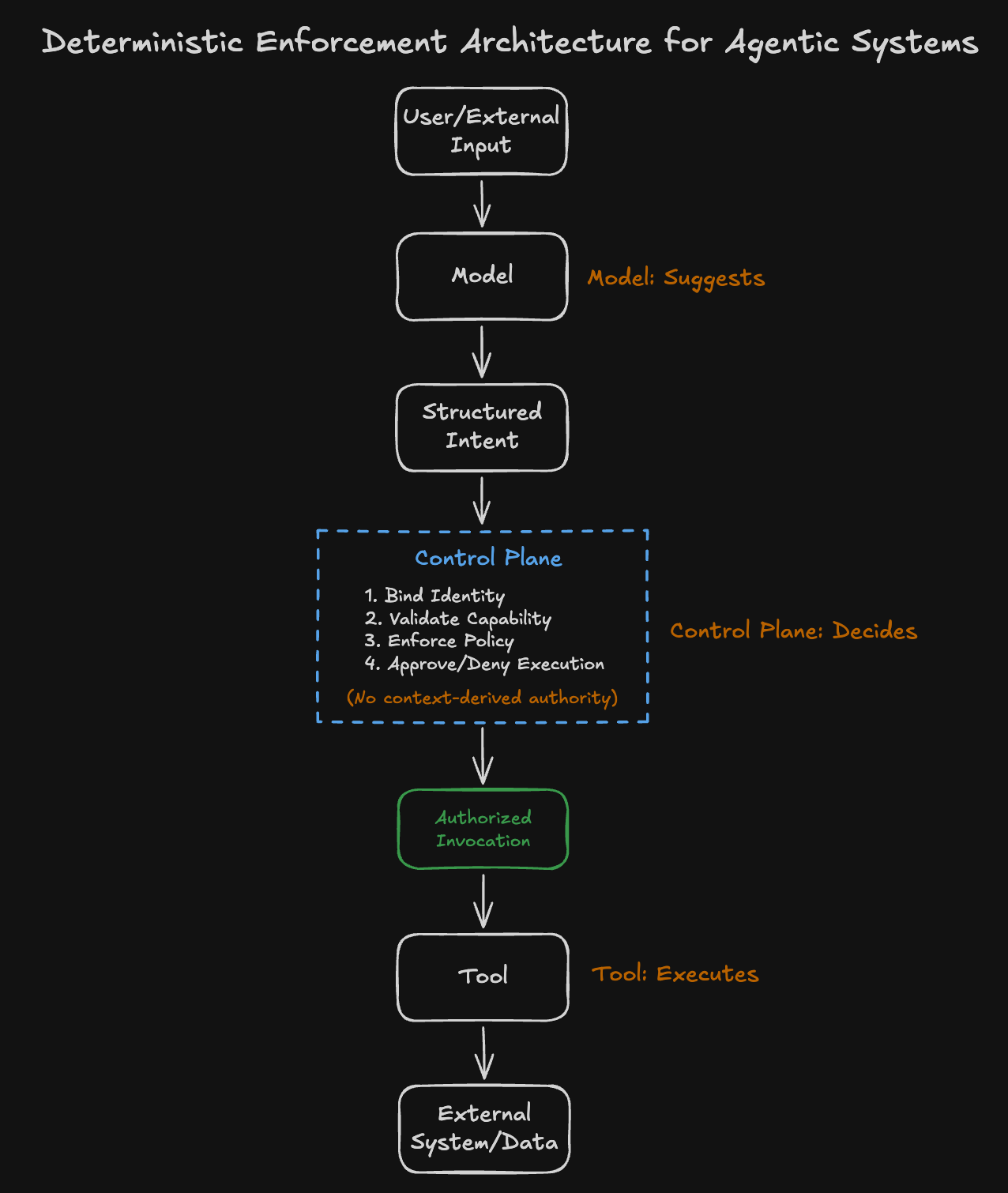
Deterministic Identity Binding
Identity collapse mitigations start with deterministic identity binding; specifically, explicit linking between who is performing the action, what action is being performed, and what level of authority is being exercised. Every action must be attributable to an identity with scoped privileges; the identity must be traceable. Reliable attribution is a requirement across tool calls, reasoning, and any downstream effects that follow the initial action.
Per-request identity scoping adds granularity. This means that every interaction would have an explicit identity context associated with it, with no residual or implicit carryover. This prevents scenarios where trust is accumulated through context shaping.
Execution time is also an opportunity to introduce identity binding. An "identity token" as part of tool calls can offer non-probabilistic attribution. This shifts the defensive posture by adding a deterministic "gate" that assesses whether the identity behind the tool call is permitted to invoke it in the first place. This explicit separation of roles offers clear delineation of privilege and identity while also preventing shared authority as a result of context manipulation.
Capability-Based Access Control
Capability-based access control (CBAC) isolates tools from model outputs and context, severing implicit trust. It removes trust from subjective sources and instead places it in capabilities that are explicitly granted, eliminating implicit authority inheritance.
A capability token that is short-lived and scoped to specific functions or actions (e.g. read_file, send_email, query_db) strictly constrains tool execution, preventing actions beyond their defined scope and defining exactly what the tool can do. Per-tool authorization policies limit which identities can invoke which tools. Each tool independently validates both capability and identity before execution, eliminating reliance on shared or global trust. Access decisions are enforced at the tool boundary, not inferred from context.
Control Plane vs Data Plane Separation
The control plane is where orchestration logic, system instructions, and authorization decisions take place. The data plane contains untrusted inputs, such as user prompts, file uploads, and retrieved content. LLM-based AI systems collapse these planes into a single context window. Therefore, data can become instruction; attackers can override intent and inject malicious behavior into the system.
Separating the control plane and data plane deterministically mitigates this problem. It achieves the goal of preventing instruction injection via untrusted inputs. Externalizing control logic such that decision-making happens outside of the model relocates authority. The model output can make suggestions or provide structured intents, but ultimately the externalized control logic holds the authority and execution validity.
Instruction boundaries must be isolated. System instructions must not be modifiable by user input and authority can never be derived from context. By isolating control from data, systems eliminate the conditions that enable context-driven escalation. If the control plane and data plane share a channel, injection is inevitable.
Behavioral vs Deterministic Controls
Behavioral controls are probabilistic and context-dependent guardrails that influence outcomes in AI-enabled workflows. They include prompt engineering, alignment tuning, and natural language constraints. These controls influence behavior, but do not enforce it.
Deterministic controls are enforceable restrictions that have binary outcomes independent of model interpretation. These include policy engines, execution gates, and identity-based authorization.
When designing and securing agentic systems, it is critical that stakeholders understand which controls can enforce security. Behavioral controls influence decisions; deterministic controls enforce them. One guides behavior, the other defines what is allowed.
These controls do not prevent model manipulation; they make it irrelevant. By enforcing identity, capability, and execution boundaries, AI systems can remain secure even when their behavioral layer is compromised.
Detection and Enforcement at Runtime
Defending AI-enabled systems often appears asymmetrical: attackers require minimal effort, while defenders must account for complex, probabilistic behavior. Security researcher Pete McKernan highlights that perceived disparity here and offers defenders actionable considerations to disprove that perception and close the gap. This approach can be extended to agentic systems.
Observability as a Security Primitive
Logs have been a staple in defenders' toolboxes for years. Being able to quickly review a log and determine not just what took place but the consequences of that action makes a defender adept. As systems scale and speed skyrockets, the bandwidth to effectively observe the ecosystem becomes very constrained if not adapted. This is where observability becomes a security primitive.
Instead of becoming the basis for visibility, logs become an element. Adding integrations where event data becomes enriched by contextual information on the system scalably automates one less thing that defenders have to iterate human reasoning cycles on. This option is sharpened when defenders understand system architecture to the point where they can granularly assert events or flows that must not occur. The AAGATE framework offers observability solutions, including but not limited to service meshes, shadow-monitor agents, and continuous risk telemetry.
Observability enables enforcement to be validated and monitored at runtime, ensuring that deterministic controls behave as expected under adversarial conditions.
Designing for Failure: Assume Compromise
Assuming the model will be manipulated is an effective starting point in securing the overall system. AI platforms are inherently sycophantic and their reasoning is influenced by context. This means that design implications need to account for this.
Minimize Blast Radius
Limit pivoting opportunities for attackers that compromise the behavioral surface. Deterministic controls such as tightly-scoped tokens and tool chokepoints act as gates between the attacker and potential negative impacts beyond the initial compromise.
Enforce Least Privilege
Deterministic identity binding enables attribution and facilitates authorization controls based on persona. Restrict what an identity can do by applying the principle of least privilege within the ecosystem.
Isolate Components
Selectively determine which components actually need to connect and interact. If the platform needs to reach sensitive data, limit what is brought into the model's awareness. "Assume compromise" can extend to context: even if a model is told not to disclose something, if it is aware of it, assume it can be socially engineered out of the model.
Use Short-Lived Credentials
Any tokens or credentials utilized in the agentic system must be short-lived. The credential lifetime must be just long enough that function is not impacted, but restrictive enough that the opportunity to replay or leverage the credentials elsewhere is extremely restricted.
The Shift from “Smart Models” to “Secure Systems”
Security is not a model property; it is an architectural property. AI system failures are not the result of insufficient alignment, but of missing enforcement. When identity is not bound, capability is not constrained, and control is not isolated, behavior becomes authority.
The challenge is not building smarter models. It is building systems that remain secure when those models are manipulated. The most effective defenses do not rely on influencing model behavior, but on enforcing deterministic constraints around it.
AI security is fundamentally an authorization problem. Until systems are designed with explicit identity, scoped capability, and enforced execution boundaries, adversarial influence will continue to translate into real-world impact.
Key Takeaways
- Context is not identity. Authority cannot be derived from interaction history or linguistic framing.
- Prompt injection is a symptom. AI security failures stem from broken attribution and authorization.
- Security is enforced, not inferred. Deterministic controls, not probabilistic guardrails, define what is allowed.